По правде сказать, когда я писал в предыдущей статье, что скоро расскажу о том, как победить ограничение на фиксированность местоположения чисел в тексте и фиксированность их длины, то не был полностью уверен, что эту проблему мне действительно удастся решить, оставаясь в рамках требований к универсальности формулы и неизменности ее размеров независимо от количества чисел в строке. К счастью, мне удалось решить эту задачу, чем сегодня и хочу поделиться с вами. Если у вас есть желание и время попробовать свои силы в этом, то буду рад, если перед прочтением статьи вы попробуете это сделать самостоятельно и напишите, что у вас получилось, возможно, ваше решение окажется куда более легким и изящным.
Напомню, что итогом предыдущей статьи стала формула, позволяющая определять сумму всех чисел в текстовой строке:
=СУММПРОИЗВ(ЕСЛИОШИБКА(ЗНАЧЕН(ПОДСТАВИТЬ(ПСТР(X;{Y};{Z});".";",";1));0))
X — анализируемая строка
{Y} — массив из начальных позиций цифр в строке
{Z} — массив длин цифр в строке
Однако, здесь начальные положения всех чисел и их длины необходимо задавать вручную как константы. Рассмотрим, как в этой задаче свести ручной труд к минимуму. Тексты для обработки у нас будут те же, что и раньше:

В рамках примера прослеживается закономерность, а именно: после каждого числа следует «руб», и перед каждым числом у нас есть определенные ключевые слова, набор которых конечен. Сразу сформируем набор этих ключевых слов, он нам понадобится в дальнейшем:

Продолжим наши размышления, разбив проблему на более мелкие части. Пусть у нас будет такая текстовая строка:

Для того, чтобы определить местоположение первого символа вырезаемого числа, нам необходимо найти начальную позицию {A} ключевого слова «Стоимость», прибавить к нему длину {L} самого этого ключевого слова и еще один символ 1, соответствующий пробелу после ключевого слова. Определив же начальное положение «руб» в тексте (назовем его {B}) мы легко получим длину искомого числа.
Соответственно в терминах нашей формулы из прошлой статьи и новых переменных, получим:
{Y} = {A}+{L}+1
{Z} = {B}-{Y} = {B}-{A}-{L}-1
Т.е. нам остается «всего лишь» определить массивы {A}, {B} и {L}, что уже не так сложно, а научившись их находить мы их легко подставим в нашу формулу. Здесь можно было бы предположить, что нам может потребоваться использовать не просто единицу в качестве одного из слагаемых/вычитаемых, а массив из единиц, по числу наших ключевых слов. К счастью, выражения вида:
{1;2;3}+{1;1;1} и {1;2;3}+1
идентичны и дают один и тот же результат:
{1;2;3}+{1;1;1} = {1;2;3}+1 = {2;3;4}.
Благодаря этому, нам не потребуется формировать еще и массив из единиц (хоть это и не невозможно, но все равно бы усложнило итоговую формулу).
При вычислении шага {A}+{L}+1 у меня было опасение, что формула вероятно будет работать некорректно, если порядок следования ключевых слов заданных в таблице «KeyW», будет отличаться от порядка следования этих же ключевых слов в строке текста, что резко уменьшило бы универсальность формулы. Логика у меня при этом была следующая. Формула при поиске {A} сформирует массив из порядковых номеров первых символов ключевых слов, встречающихся в тексте и в этом массиве сперва будет порядковый номер ключевого слова перед первым числом, затем перед вторым и так далее, а затем к этому массиву мы прибавим массив длин ключевых слов {L}, порядок следование которых в текстовой строке и в списке «KeyW» может не совпасть, и в итоге получим неверные номера символов, с которых следует начать вырезать числа. На самом же деле, массив из {A} формируется, конечно же, не по увеличению порядкового номера символа в анализируемой текстовой строке, а в том же самом порядке, как соответствующие ключевые слова расположены в списке, и, соответственно, в том же порядке, в котором мы получаем длины этих ключевых слов. То есть, если первое ключевое слово в тексте встречается вовсе не первым, то все равно функция поиска будет искать именно его первым и для него первого вернет его расположение, затем перейдет ко второму ключевому слову, и вернет его местонахождение в тексте, которое вполне может оказаться перед расположением первого по списку ключевого слова и т.д., таким образом, будет сформирован массив из {A}, которые будут соответствовать порядку ключевых слов именно в списке, а не просто по возрастанию начальной позиции ключевого слова в тексте. Схематично это я попытался изобразить следующей анимацией:

Не буду утомлять долгими рассказами о том, какие мне еще мысли, в том числе и ошибочные, приходили в голову во время решения этой задачи и перейду к полученному результату для каждого из массивов {A}, {B} и {L}:
Массив расположения первых символов ключевых слов в анализируемой строке:
{A} = ЕСЛИОШИБКА(ПОИСК(KeyW[Words];[@Текст]);0)
Тут все довольно просто — производится поиск всех ключевых слов в текстовой строке, если слово не было найдено, вместо места его расположения будет указан 0. Рассмотрим вычисления по этапам на примере строки с текстом «Транспортные расходы 20.05 руб. Налог 15.15 руб. Комиссия 10.01 руб. Цена услуг 100.02 руб.» (я буду пропускать совсем уж очевидные шаги):
Этап 1: {"Цена услуг":"Транспортные расходы":"Налог":"Комиссия":"Стоимость"} — получили набор ключевых слов
Этап 2: {70:1:33:50:#ЗНАЧ!} — нашли начальную позицию для каждого слова. Слово «Стоимость» отсутствует в текстовой строке, поэтому вместо его расположения получили ошибку
Этап 3: {70:1:33:50:0} — заменили ошибку #ЗНАЧ! на 0
Массив расположения первого символа слова «руб», которое встречается в анализируемой строке несколько раз:
{B} = ЕСЛИОШИБКА(ПОИСК("руб";[@Текст];{A});0)
{B} = ЕСЛИОШИБКА(ПОИСК("руб";[@Текст];ЕСЛИОШИБКА(ПОИСК(KeyW[Words];[@Текст]);0));0)
Здесь, в отличие от предыдущей формулы, мы задействовали третий необязательный аргумент функции ПОИСК, а именно начальные позиции для поиска, в качестве которых у нас будет выступать массив {A}. Сделано это по той причине, что «руб» встречается в тексте несколько раз, и нам важно задать не просто одну начальную позицию поиска, но еще и сдвигать ее для каждого последующего вырезаемого из текста числа, т.к. в противном случае ПОИСК нам вернет только первое расположение «руб», проигнорировав все последующие. В рамках той же текстовой строки получим:
Этап 1: {70:1:33:50:0} — начальные позиции ключевых слов в тексте, после которых нам следуюет искать «руб»
Этап 2: {88:28:45:65:#ЗНАЧ!} — получили начальные позиции всех вхождений слова «руб» в текстовой строке
Этап 3: {88:28:45:65:0} — заменили ошибку #ЗНАЧ! на ноль
Массив длин ключевых слов:
{L} = ДЛСТР(KeyW[Words]) — это, пожалуй, самое простое в нашей формуле:
Этап 1: {"Цена услуг":"Транспортные расходы":"Налог":"Комиссия":"Стоимость"} — снова получили набор ключевых слов
Этап 2: {10:20:5:8:9} — определили длины этих слов
Теперь, используя данные последних этапов вычислений, попробуем рассчитать {Y} (начальную позицию искомых цифр в тексте):
{Y} = {A}+{L}+1 = {70:1:33:50:0} + {10:20:5:8:9} + 1 = {81:22:39:59:10}.
10 — выделена здесь не случайно. Почему? А потому, что в нашей текстовой строке последнее ключевое слово «Стоимость» не встречается, но тем не менее, мы вычислили и его длину тоже, что привело к ошибке в расчётах. На ум напрашивается решение — если какое-то слово не было найдено, то после итоговых расчётов соответствующий ему элемент массива необходимо умножить на ноль, а т.к. не найтись может любое слово, то нам необходимо уметь избирательно умножать на ноль соответствующие элементы массива. Поэтому формулы {Y} = {A}+{L}+1 и {Z} = {B}-{A}-{L}-1 должны быть дополнены:
{Y} = ({A}+{L}+1)*{N},
{Z} = ({B}-{A}-{L}-1)*{N},
где {N} массив из нулей и единиц, при этом 1 соответствует найденному ключевому слову, а 0 — слову, которое найти не удалось.
Получить такой массив достаточно легко, воспользовавшись формулой:
{N} = --ЕЧИСЛО(ПОИСК(KeyW;[@Текст]))
Ее расчет для нашего случая будет таким:
Этап 1: {"Цена услуг":"Транспортные расходы":"Налог":"Комиссия":"Стоимость"}
Этап 2: {70:1:33:50:#ЗНАЧ!}
Этап 3: --{ИСТИНА:ИСТИНА:ИСТИНА:ИСТИНА:ЛОЖЬ}
Этап 4: {1:1:1:1:0}
«--» в формуле это двойной минус, применение которого является одним из самых простых и распространенных способов из ИСТИНА получить 1, а из ЛОЖЬ — 0.
Таким образом, для {Y} получим:
{Y} = {81:22:39:59:10}{1:1:1:1:0} = {81:22:39:59:0} Не буду приводить вычисления для {Z} — они полностью аналогичны. Теперь же, после того как мы смогли рассчитать все параметры, нам их остается только добавить в формулу из начала статьи: {=СУММПРОИЗВ(ЕСЛИОШИБКА(ЗНАЧЕН(ПОДСТАВИТЬ(ПСТР(X;{Y};{Z});".";",";1));0))}
Заменяем {Y} и {Z} на промежуточные переменные: {=СУММПРОИЗВ(ЕСЛИОШИБКА(ЗНАЧЕН(ПОДСТАВИТЬ(ПСТР(X;({A}+{L}+1)*{N};({B}-{A}-{L}-1)*{N});".";",";1));0))}
И в итоге формула будет выглядеть так:
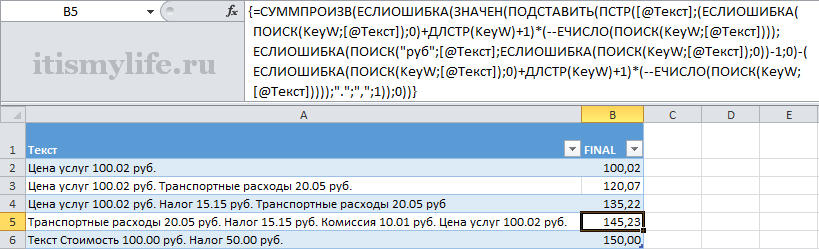
Она же текстом:
{=СУММПРОИЗВ(ЕСЛИОШИБКА(ЗНАЧЕН(ПОДСТАВИТЬ(ПСТР([@Текст];(ЕСЛИОШИБКА(ПОИСК(KeyW;[@Текст]);0)+ДЛСТР(KeyW)+1)*(--ЕЧИСЛО(ПОИСК(KeyW;[@Текст])));ЕСЛИОШИБКА(ПОИСК("руб";[@Текст];ЕСЛИОШИБКА(ПОИСК(KeyW;[@Текст]);0))-1;0)-(ЕСЛИОШИБКА(ПОИСК(KeyW;[@Текст]);0)+ДЛСТР(KeyW)+1)*(--ЕЧИСЛО(ПОИСК(KeyW;[@Текст]))));".";",";1));0))}
Конечно, «руб» здесь можно было заменить на значение в какой-либо ячейке, но, думаю, при необходимости, вы сможете с легкостью сделать это и сами. Не забывайте, что формулы массива следует вводить при помощи Ctrl+Shift+Enter.
У полученной формулы есть и ограничения. Куда уж без них. Если одно или несколько ключевых слов дублируются в одной текстовой строке, то будет найдено только первое совпадение, и как следствие только одна цифра, соответствующая такому дублирующемуся ключевому слову.
Задачу по нахождению чисел можно было поставить иначе, например, найти все числа и сложить. Почти тоже самое, но нет. Мне, для моих целей было важно складывать не все числа подряд, а только после определенных ключевых слов, т.к. это напрямую относится к той практической задаче, которая передо мной стояла, и о которой я наконец смогу рассказать, после того, как мы с вами научились выполнять такие действия над текстовой строкой, как частичный ВПР и сложение чисел в текстовой строке. Оставайтесь с нами!
One thought on “Excel. Сложение чисел из текстовой строки, следующих после ключевых слов”